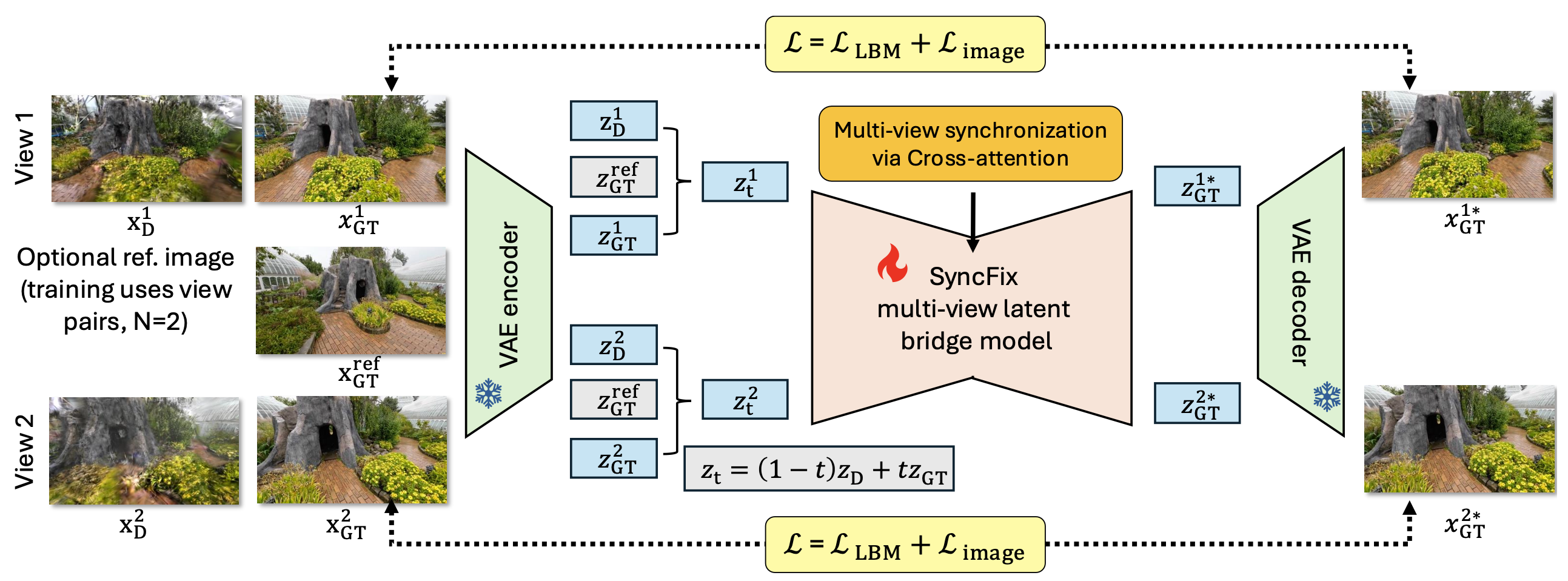
We present SyncFix, a framework that enforces cross-view consistency during the diffusion-based refinement of reconstructed scenes. SyncFix formulates refinement as a joint latent bridge matching problem, synchronizing distorted and clean representations across multiple views to fix the semantic and geometric inconsistencies. This means SyncFix learns a joint conditional over multiple views to enforce consistency throughout the denoising trajectory. Our training is done only on image pairs, but it generalizes naturally to an arbitrary number of views during inference. Moreover, reconstruction quality improves with additional views, with diminishing returns at higher view counts. Qualitative and quantitative results demonstrate that SyncFix consistently generates high-quality reconstructions and surpasses current state-of-the-art baselines, even in the absence of clean reference images. SyncFix achieves even higher fidelity when sparse references are available.
Distorted renderings from multiple viewpoints $x_D$ are encoded into latent representations and transported toward clean targets $x_{GT}$ using latent bridge matching. SyncFix learns a joint latent bridge over multiple views, coupling latent trajectories through cross-view attention to enforce multi-view consistency during refinement. The model is trained using view pairs ($N=2$) but generalizes to an arbitrary number of views at inference. Optional reference images can be provided to guide refinement. Here $z_D$ denotes distorted latents, $z_{GT}$ clean target latents, and $z_t = (1-t)z_D + t z_{GT}$ the bridge interpolation between them.
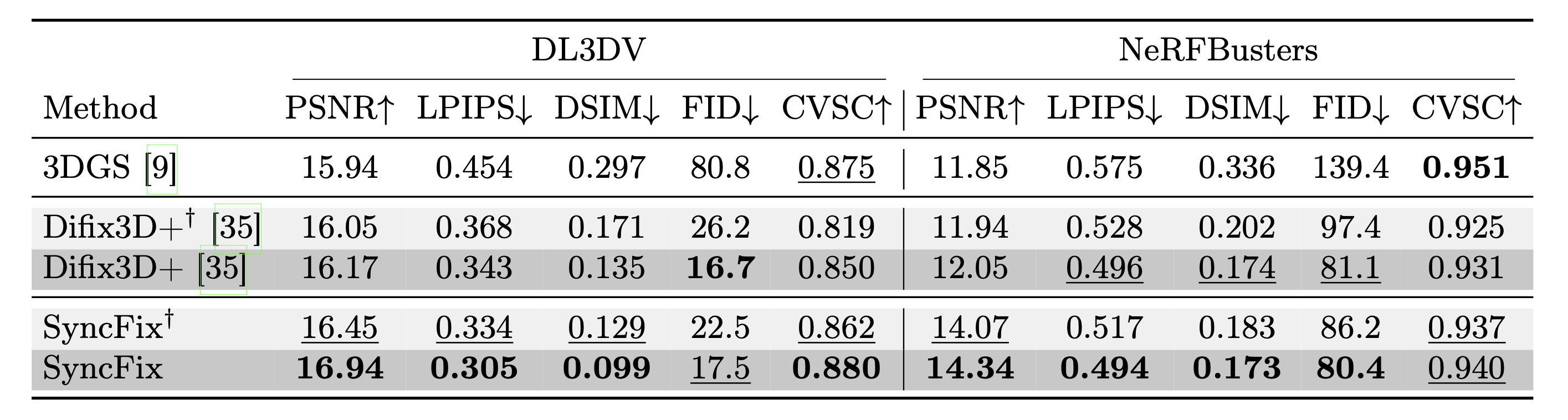
SyncFix exceeds Difix3D+ by 0.77 dB on PSNR and reduces LPIPS by 0.038 on DL3DV test set, similar for their without-reference variants. Notably, SyncFix decreases DreamSim score by 27 percent compared to Difix3D+ and FID by more than four times compared to the 3DGS renderings. SyncFix achieves better PSNR and CVSC than Difix3D+ on the Nerfbusters dataset.
Difix3D+ mitigates the noises and sharpens the renderings. However, Difix3D+ struggles in multi-view context, i.e., changing geometry of the objects and overfitting to view-dependent artifacts. In comparison, our method reduces artifacts globally through a joint refinement of the renderings and maintains a more 3D-consistent geometry of the scene.

3DGS reconstructions contain severe artifacts and geometric distortions. Difix3D+ improves the appearance of individual renderings but struggles to extrapolate to unseen regions and often produces unstable structures across views. In contrast, SyncFix generates plausible reconstructions that remain consistent across viewpoints, recovering coherent object geometry and scene structure.

We compare SyncFix with GenWildSplat, a recent state-of-the-art method for sparse-view 3D reconstruction from unconstrained in-the-wild images. Each video below shows a side-by-side qualitative comparison, with GenWildSplat on the left and SyncFix on the right. The GenWildSplat results were evaluated and shared by the GenWildSplat authors via email communication. We thank the authors for providing these comparisons and include them here with proper credit. Please refer to the GenWildSplat project page, paper, and code repository for details about their method.
Left: GenWildSplat | Right: SyncFix
Left: GenWildSplat | Right: SyncFix
Left: GenWildSplat | Right: SyncFix
Left: GenWildSplat | Right: SyncFix
Left: GenWildSplat | Right: SyncFix
Left: GenWildSplat | Right: SyncFix
Left: GenWildSplat | Right: SyncFix
Left: GenWildSplat | Right: SyncFix
Left: GenWildSplat | Right: SyncFix
GenWildSplat results are credited to Gupta et al. Please cite their paper/project page when referring to these comparisons.
@article{li2026syncfix,
title={SyncFix: Fixing 3D Reconstructions via Multi-View Synchronization},
author={Li, Deming and Yadav, Abhay and Peng, Cheng and Chellappa, Rama and Bhattad, Anand},
journal={arXiv preprint arXiv:2604.11797},
year={2026}
}@article{gupta2026genwildsplat,
title = {Generalizable Sparse-View 3D Reconstruction from Unconstrained Images},
author = {Gupta, Vinayak and Lin, Chih-Hao and Wang, Shenlong and Bhattad, Anand and Huang, Jia-Bin},
journal = {CVPR},
year = {2026}
}